
让不懂建站的用户快速建站,让会建站的提高建站效率!

最近一段时代中国大模子边界变得特地烦嚣,最蹙迫的话题便是各大模子公司的“价钱战”。
而事实上,这场让字节、阿里、百度、智谱等纷纷卷入的大混战,领先却是一个“好意思妙”的“金融公司”所掀翻的。
5月6日,量化对冲基金幻方旗下的AI团队深度求索,发布了最新的模子,同期,告示把API价钱下调,降价幅度之大,使得它的价钱仅仅GPT-4 Turbo的百分之一水平。很快,它激发了四百四病。之后字节和阿里的连接跟进,使得价钱战发扬铺开。

深度求索,和它模子的名字“DeepSeek”似乎对大多数东说念主来说都显得有些生分,但在模子讨论者和开源圈子里,它一度是被说起最多的模子和设备厂商之一,以致在Mistral和Llama占据总揽地位时,DeepSeek也有一批古道拥趸。许多设备者尤其合计它的数学和推理才气极强,与那些追求嘲谑吟诗作赋的模子区别显著。
最新的一个动作是,离开OpenAI的大神Andrej Karpathy也开动眷注DeepSeek的账号。
主业二级阛阓走动,却作念起了AGI;低调特地,却决定着扫数行业走向;不何如宣传,却受到社区自来水一派好评......这一系列的反差让这家公司更显好意思妙。
不外这种“好意思妙”可能并不会赓续很深切。多位接近幻方的东说念主士暴露,幻方对深度求索接下来的权术是,让它孤立面对阛阓。它将有可能成为看起来款式已定的中国大模子江湖里,终末一个玩家,也注定会是一个很能搅局的玩家。
被低估的DeepSeek
就像深度求索是价钱战的“发起者”这件事被许多东说念主冷落一样,DeepSeek这次的技能改进通常零落商量。在论说深度求索这家公司之前,咱们不错先望望这次发布的新模子上,DeepSeek的技能改进。
这次DeepSeek-V2对架构层面作念了改进,这是许多国产以致人人范围的开源基座模子少有的尝试。
在架构方面,DeepSeek-V2 收受了Transformer 架构,其中每个 Transformer 块由一个提神力模块和一个前馈蚁集(FFN)构成。讨论词,对于提神力模块和 FFN,讨论团队想象并收受了改进的架构。
一方面,该讨论想象了MLA(Multi-head Latent Attention): 一种更好、更快的提神力,可通过减少KV缓存确保高效推理。
另一方面,对于FFN收受了高性能MoE架构DeepSeekMoE,以经济的老本查验苍劲的模子。
DeepSeek 草创的 Sparse 结构 DeepSeekMoE 与 MLA 架构的结合,鼓吹了 DeepSeek-V2 栽植成果和性能。此模子仅需极小的内存用量(终点于对应密集型(Dense)模子的1/5~1/100),就可阐述出相似于 70B~110B 密集型(Dense)模子的野心才气。
模子的高成果径直转换为显耀的老本省俭——在8卡H800机器上,DeepSeek-V2 的输入模糊量可达每秒超越 10 万 tokens,输出超越每秒5万 tokens。
DeepSeek-V2模子和论文皆备开源,可免用度于营业用途。
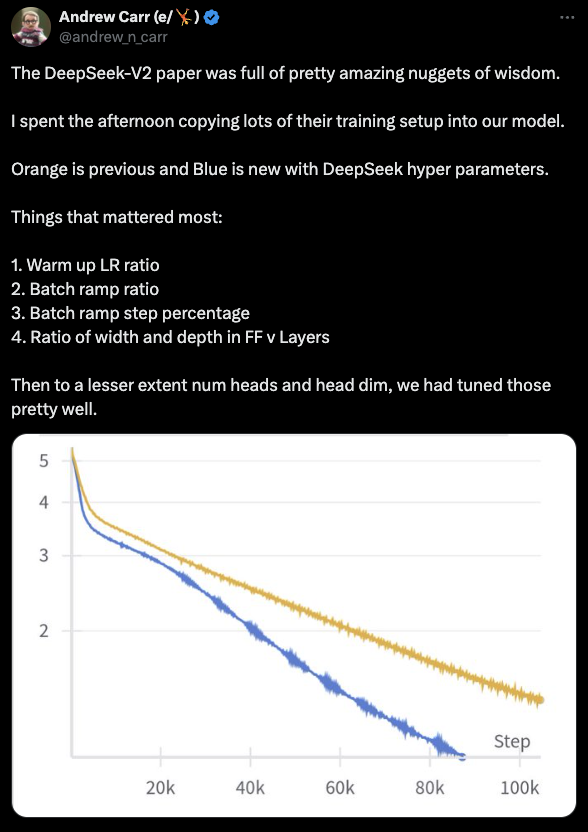
OpenAI前职工Andrew Carr从DeepSeek-V2论文中获得灵感,将其查验缔造欺骗于我方模子
DeepSeek-V2每百万tokens输入/输出价钱远低于行业平均水平,推理的老本的大幅裁汰,进一步裁汰了使用大型言语模子的门槛,举例在AI智能体等场景,需要频频对话调用,需要巨额token数目。价钱的裁汰,有望带来更快的营业化落地,且可能栽植用户体验。
一位AI设备者在DeepSeek-V2发布后示意,在他设备的AI游戏中,原来由大模子上演的把持东说念主是不会接头历史音问。这就导致大模子的恢复并不接头用户还是掌抓的信息,难以给出真实有启发性的、各样性的恢复。而现时DeepSeek API的价钱不到市面上同头绪大模子的十分之一,他也不错尝试接头加入历史音问了。
挑起价钱战后,需要更多弹药了
DeepSeek-V2是深度求索赓续的模子更新的最新进展,它的才气栽植显著,闪设备者们记取了DeepSeek这个模子系列,而更蹙迫的,是DeepSeek的站稳脚跟,让深度求索不错被按照一家模子层的公司来估值。
据知情东说念主士对硅星东说念主称,幻方对深度求索有孤立拆分上市的权术。而这次“价钱战”的进展,正在让这个权术的进度加速。
深度求索挑起的“价钱战”,领先对它来说是个“自讨论词然的事情”。
5月6日深度求索(DeepSeek)发布DeepSeek-V2时示意,DeepSeek-V2汉文抽象才气(AlignBench)开源模子中最强,与GPT-4-Turbo,文心4.0等闭源模子在评测中处于归并梯队。英文抽象才气(MT-Bench)与最强的开源模子LLaMA3-70B同处第一梯队,超越最强MoE开源模子Mixtral 8x22B。常识、数学、推理、编程等榜单遣散也位居前哨。同期撑持128K高下文窗口。
DeepSeek-V2领有2360亿参数,其中210亿个活跃参数。160位人人,其中有6位在生成中活跃。DeepSeek-V2在包含8.1万亿token的语料库上进行预查验,并通过监督微调(SFT)和强化学习(RL)来进一步栽植模子才气。
价钱战是这些模子才气的“附加物”——在才气接近第一梯队闭源模子的前提下,DeepSeek-V2 API的订价为每百万tokens输入1元、输出2元(32K高下文),价钱仅为GPT-4-Turbo的近百分之一。深度求索对这个价钱的讲明是,它并不是补贴,现货白银投资而是,这“现时便是大限制做事的价钱,不赔本,利润率超50%”

一方面技能过硬径直把价钱打下来,另一方面,这些查验部分的资金,并不像自后跟进价钱战的一批创业公司那样来自VC们的融资——深度求索现时的弹药是幻方我方的。
而价钱战发扬打响后,事情开动起变化。
跟着诸多资金愈加浑厚的大厂的跟进,这场“价钱战”为代表的模子阛阓的强烈竞争开动显得更心焦。
幻方中枢业务所处的量化基金边界也在资历诊治,此前的烧我方的钱,让讨论团队不错解放而心无旁骛的讨论的面貌,在面对愈加强烈的外部竞争压力下,也在发生变化。不烧VC的钱的景况可能改变。
终末的玩家登场
这意味着深度求索可能成为中国大模子江湖里终末一个蹙迫玩家。
由于不在大模子的“圈子”里,深度求索的发展历程鲜少被说起。但它其实并非一个“不务正业”的临时组织。
提到深度求索,绕不开的便是其背后的量化投资公司幻方量化,幻方量化是一家依靠数学与野神思科学进行量化投资的对冲基金公司。
幻方独创团队自2008年起探索自动化走动。2015年幻方量化创立,依靠数学与东说念主工智能进行量化投资,并在2016年头次将深度学习模子欺骗于实盘走动,使用GPU进行野心,并赓续参预AI算法讨论。
尔后,幻方束缚壮大AI团队,转向AI驱动的量化计策,并靠近算力挑战。2019年至2021年间,幻方接踵自主研发了“萤火一号”与“萤火二号”AI集群,其中“萤火二号”投资达到10亿元,极大栽植算力撑持。
而建造萤火集群的经由中,深度求索的前身出现。
在ChatGPT横空出世时,东说念主们发现时中国领有高性能GPU芯片最多的不是东说念主工智能公司,而是幻方。据国盛证券研报,在云算力端,那时除了几家互联网公司,就唯有幻方有超越1万张A100芯片储备。
动作一个需要GPU作念量化的金融机构,囤积一些显卡很肤浅。但买了1万张况兼我方建起集群,就“不肤浅”了。
事实上,幻方的集群领先便是在作念金融以外的事情。
据又名很早斗争过幻方的算法科学家称,“幻方那时真实有巨额的卡,而早期他们买这些卡是在作念‘慈善’——他们那时其实莫得一齐给我方用,而是用了很低的价钱提供给各式需要更多的卡作念算法讨论的机构来使用。”公开贵寓不错查询到,在萤火建成后的几年,有多篇登上nature等顶级期刊的论文,背后算力是由幻方撑持。
这个决定当然很大程度来自独创东说念主。
公开贵寓里,对于幻方独创东说念主梁文锋的信息未几。又名很早斗争过幻方独创东说念主梁文锋的大模子创业者称,梁文锋对生成式AI技能是有我方的很深的讨论和追踪的。他们第一次碰面时,这位掌管着千亿资金的“金融家”一上来就拿这位明星创业者早期发过的一篇论文中的一个公式,向后者请问,并提议了我方的想法。这让他印象深刻。
而幻方在搭建“萤火”集群中心团队的同期,也积极招募了一批算法科学家。多个业内AI讨论东说念主士称,幻方在这些年引诱了一巨额才气很强的华东说念主AI从业者。又名从Google总部归国加入幻方的职工就曾刻画幻方里面文化很像Google好意思国。“雇主本东说念主每天都在写代码、跑代码。”
幻方那时派遣这些科学家作念AI基础门径层产物,以及一些包括AI for Science的纯讨论的使命。
这些若干都让东说念主意想OpenAI的文化和氛围。
2023年5月,幻方正式把萤火团队的定位辘集在作念大模子,设立孤立新组织,定名为“深度求索”,并强调将专注于作念真实东说念主类级别的东说念主工智能。其方向不仅仅复刻ChatGPT,还要去讨论和揭秘通用东说念主工智能,尝试拓宽东说念主类对东说念主工智能的意志和默契,此前已发布包括搀杂人人言语大模子、代码大模子、视觉言语模子在内的多个模子:

大模子行业的产物负责东说念主orange.ai向硅星东说念主示意,深度求索的显卡依托幻方的积聚,在国内大模子创业公司里的显卡数目应该是前三的。这个团队对技能追求相比高,技能实力瑕瑜常强的。他们在国内最早发布了MoE模子,还径直开源。最近发布的V2模子则在MoE架构上进行了纷乱的优化,让推理老本下跌了至少一个数目级。还有一些视觉有关的模子业界口碑也很好。
“仅仅他们很少宣传,一般用户都不知说念。而且之前莫得参预作念C端产物,这么可能会产生一种模子见解很好,关联词端到端体验不够好的问题,比如一些特定任务的提醒顺从方面照旧有朝上空间的。”
显著,这些挑战,要是以一个愈加孤立的“大模子公司”的身份来量度和措置,就愈加容易了。

而就在5月15日,深度求索告示DeepSeek Chat已恰是通过国度备案,告别内测,发扬向公众开下班作。
本年是幻方设立的第九年,在“异邦货”量化基金边界它是一个全华班的原土化特例,用一套接地气又念念路新奇的打法改变已有款式取得了生效。
今天它正在让这个故事在大模子边界重演。深度求索也在成为看似款式已定的中国大模子行业里的最专有的搅局者。
